こんにちは! アカツキゲームス クライアントエンジニアのSuです。
この記事は Akatsuki Advent Calendar 2025 24日目の記事です。メリークリスマス!
はじめに
学生時代に強化学習の研究を少したので、久しぶりに強化学習をやりたいな〜の気持ちで本記事を書きました。今回はGymnasiumというPythonライブラリを使用した経験を紹介したいと思います!
強化学習とは?
強化学習(Reinforcement Learning)は簡単にいうと、エージェントが環境の中でアクションと実行し、その結果から学習し、エージェントがよりいい結果を出力できるようにアクションを選択する方法を最適化することです。
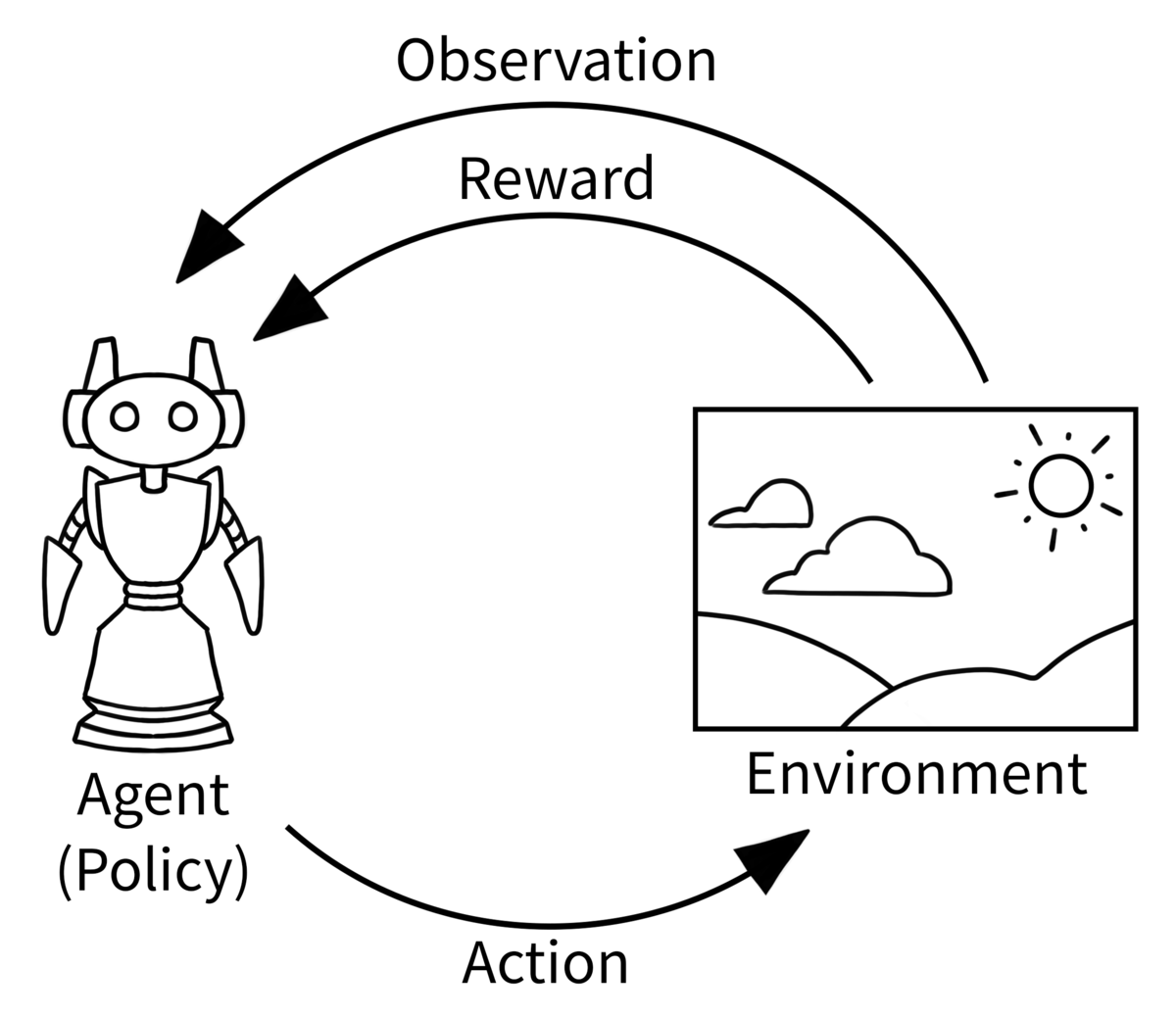
(Gymnasium-Basic Usageより)
例えば、レーシングゲームで自動運転のエージェントを作るとしたら:
- Action: 加速、減速、方向を変わる
- Observation: ゴールまでの距離、壁の方向と距離、経過時間...
- Reward: 走行した距離、壁にぶつかる回数...
エージェントがアクションを決めるアルゴリズムは強化学習分野の重要トピックです。Q-Learning、PPO、SAC、最近でたDAPOなど、アルゴリズムの進化速度はとても早いです。この記事は深掘りしませんが、興味がありましたらぜひ調べてみてください!
Gymnasiumとは?
2021年にOpenAI Gym library の開発チームが Gymnasium に移転しました。
強化学習環境開発・訓練に特化した Python ライブラリです。
(https://gymnasium.farama.org/ より)
今回は公式ドキュメントにある例のマップを改造して、そのマップ上にプレイヤー、ゴール、トラップがあります。プレイヤーを動かして、トラップをできるだけ踏まないように、終点まで移動するタスクをAIに学習させ、その学習結果を評価したい思います。
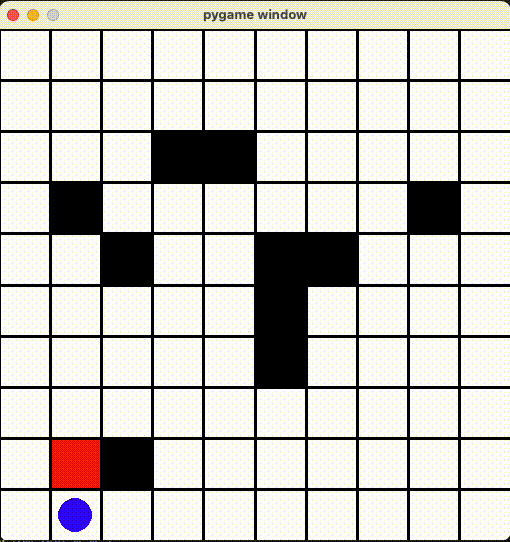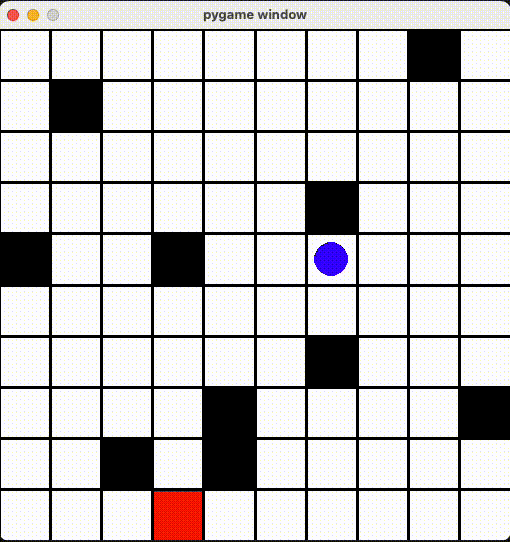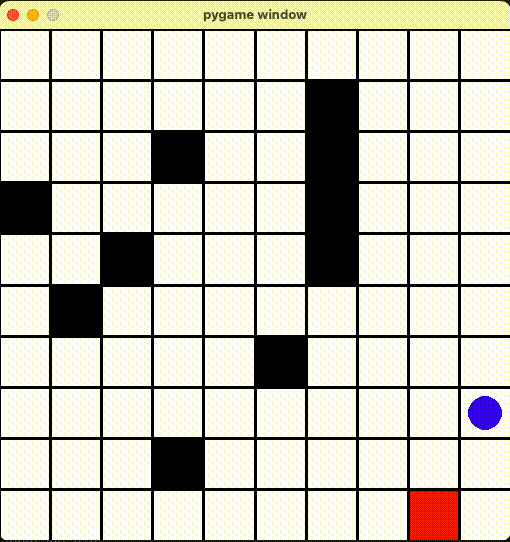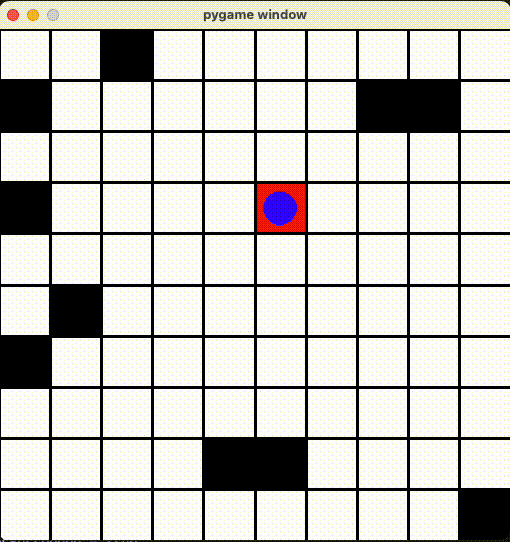
環境の作成
まず、Gymnasium環境クラス gymnasium.Env 3パートで構成されます:初期化、更新、描画です。それと下記の情報はコンストラクタで定義します:
- Observation の最大最小値(observation space)
- 可能な Action(action space)
- 描画、デバッグパラメター(metadata)
- ランダムシート(np_random) → 特定結果を再現したい時に使うと便利
初期化
処理は reset() に入れます。環境を初期状態にする処理です。最初の Observation を返します。処理は 1 episode(タスク開始〜終了)ごとに実行されます。今回はプレイヤー、ゴール、トラップの位置をランダムに生成する処理を書きました。Observation はプレイヤー、ゴール、トラップの位置にします。
更新
実行するActionを step() 関数に渡して、環境はどう変化するかとこの行動はいいかどうかを返す。今回の Action は移動方向で、関数内にはプレイヤーの位置を更新、ゴールについたら点数を与える、トラップを踏んだら減点にしました。
描画
render() 関数に定義されます。今回は青い丸がプレイヤー、赤い丸がゴール、黒い丸がトラップ、それとマスを PyGame ライブラリで描画しました。
パッケージ
環境できたら、利用しやすくためパッケージ化します。パッケージ化すると、便利な Wrapper が使えます。Observation を他の形式に変更する(例えば、プレイヤーとゴールの位置ではなく、その相対位置に変更)にはよく使いします。
エージェント
Observation を見て、どういう Action を取るかを決めるルールです。Q-Learning、PPO、SAC というアルゴリズムの部分です。自分で実装するのもいいし、公式おすすめのライブラリ Stable-Baselines3 を使うと便利です。パッケージされた Gym 環境があれば下記のように簡単にモデル作れます。複数環境で並行学習もできます。
学習
環境から返した点数で今回選んだActionを評価して、次同じObservationが来た時に同じActionを選ぶかどうか、アルゴリズムを修正します。Stable-Baselines3のドキュメントを参考すれば各パラメターの意味が書かれていますので、ここは割愛します。
ログ
Stable-Baselines3 は TensorBoard 出力できます。TensorBoard を使用してログを出力できます。学習の過程を図で表示できます。学習足りているかどうかの確認やパラメター調整する際にかなり参考になりました。
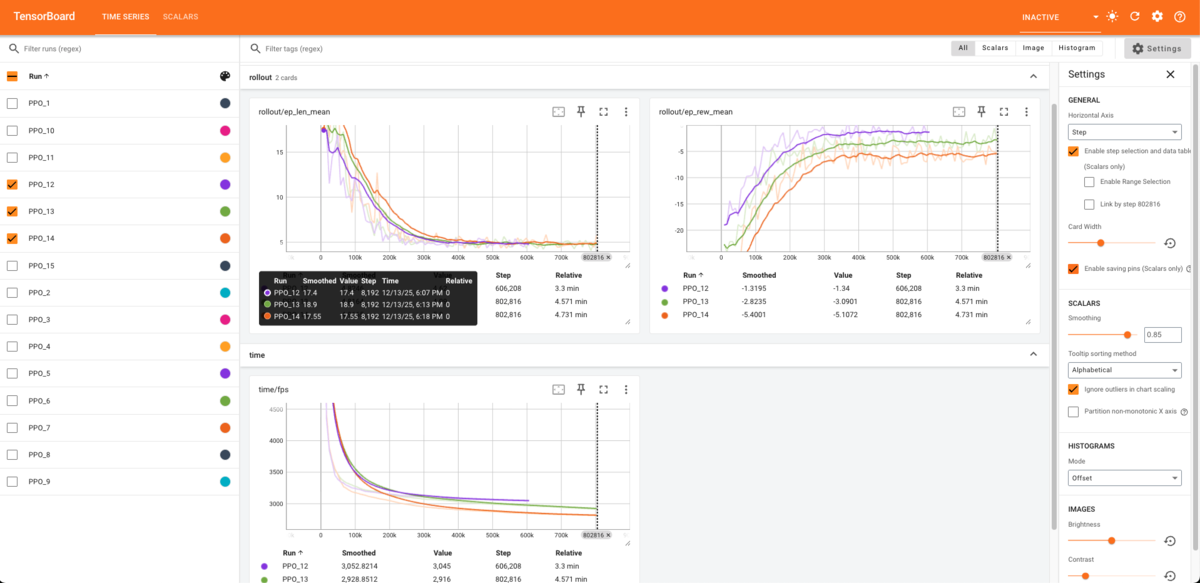
訓練結果を評価
Stable-Baselines3で学習したモデルを保存できます。その保存したモデルをロードすれば、与えた Observation に対して Action を出力します。
<gist>
よし!最強のAIを作ったので、早速モデルを試すぞ!
あれ、なんか動かないだけど......
移動しない
最初の問題は、壁にぶつけたら移動しなくなった問題です。これを解決するために、「前回と同じ位置なら減点」するRewardを追加してみましたが...
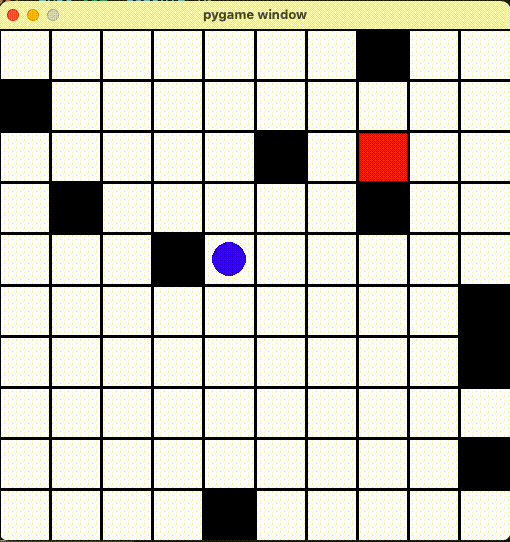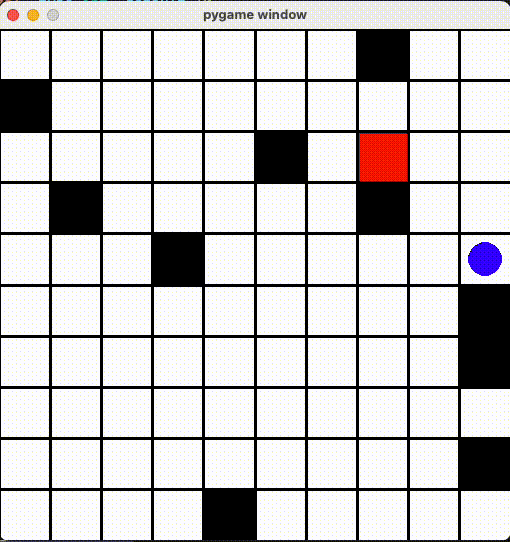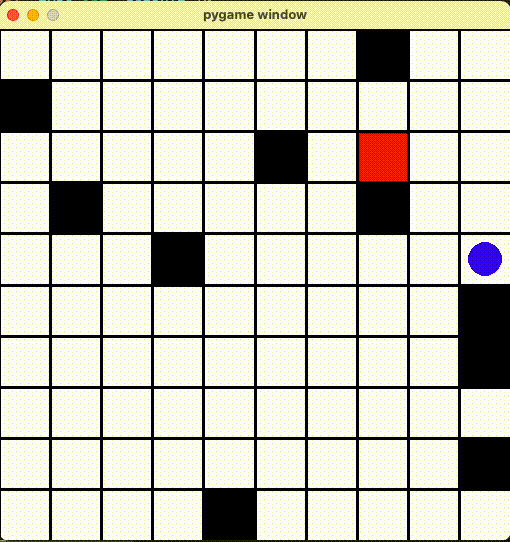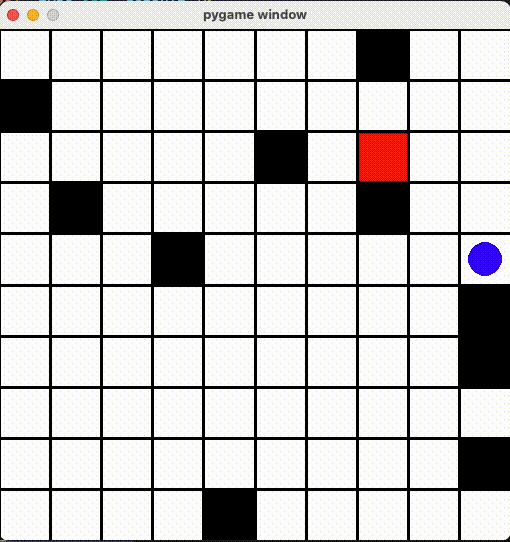
ずっと隣のマスに行ったりきったり
「同じ場所じゃなければいい」とエージェントもその抜け道を見つけて、ずっと同じマスに行ったりきったりしていました...
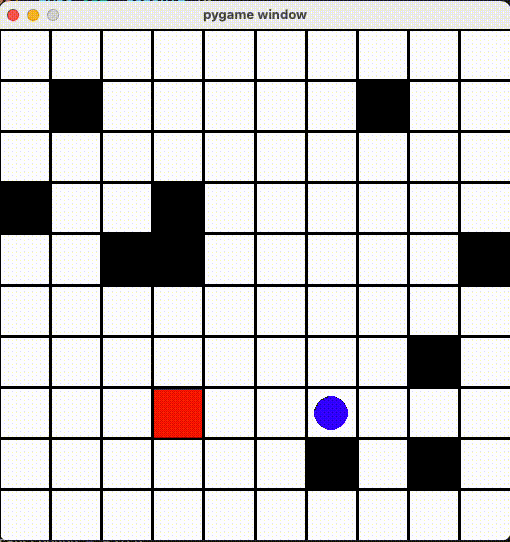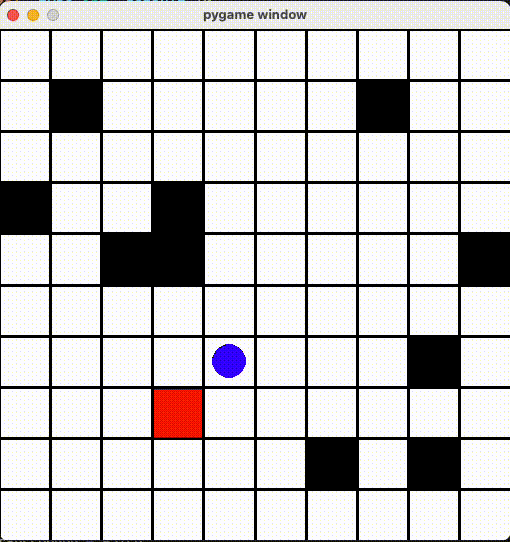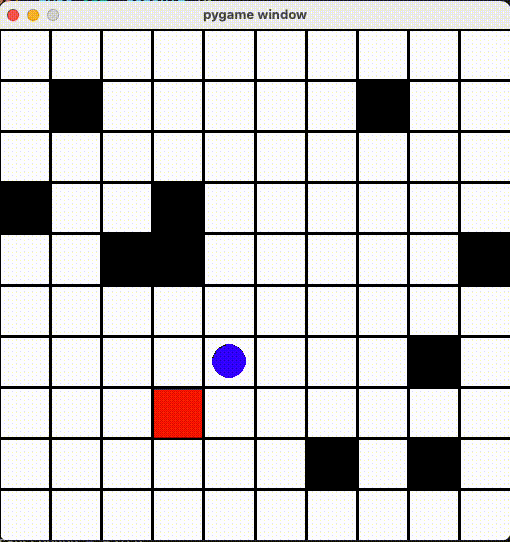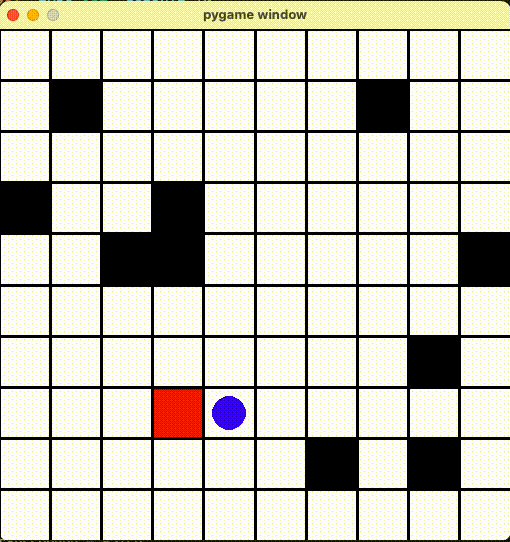
AIちゃんをちゃんと動かせるため、「すでに経過した場所に移動すると減点する!」ように Reward 修正しました。
色々調整した結果、それっぽい動きになった!
時々トラップに踏むですが、避けるように頑張ってるを感じてます。
より広いマップ
15x15のマップで改めて学習させました!10x10より学習時間2倍かかったが、成果は悪くないと思います。
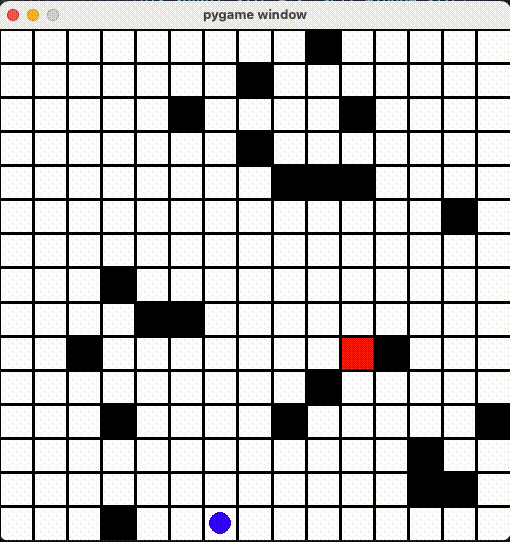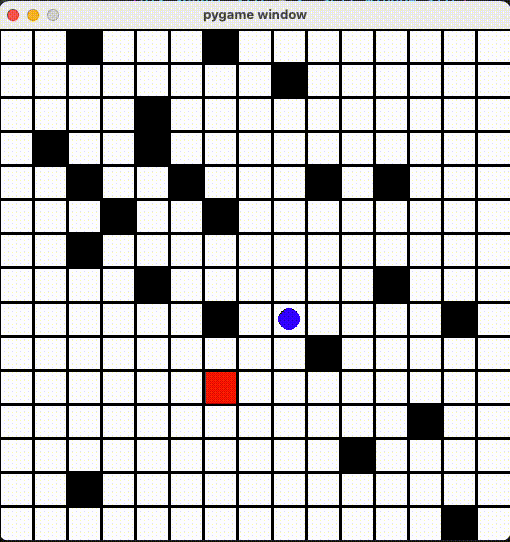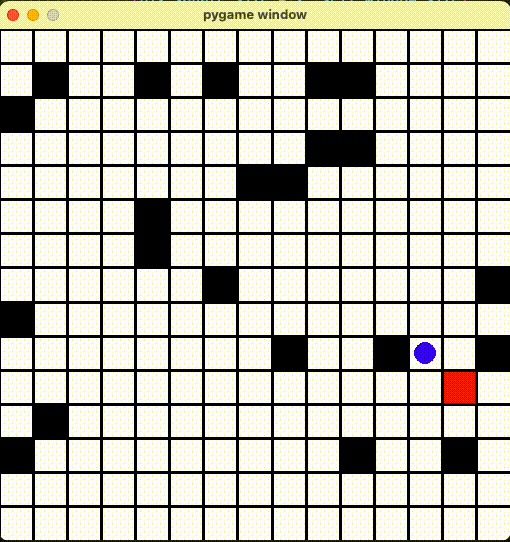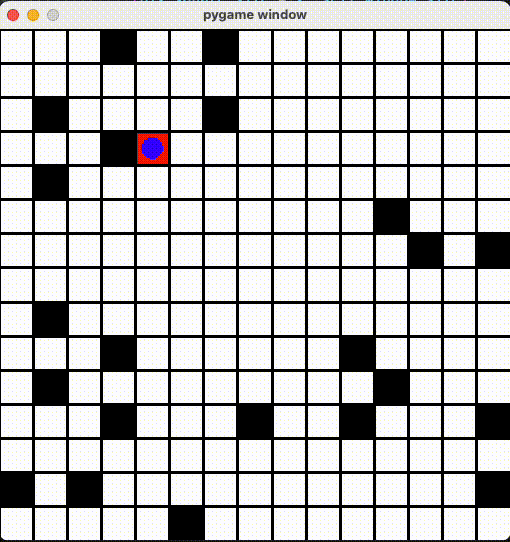
Github Repo
今回使用したコードをGitHubにアップロードしたので、興味がある方はぜひ触ってみてください!
最後に
調整してAIをどんどん成長させるのも楽しいですが、適切なRewardを設定するのが難しいと実感しました。それと、個人的な感想ですが、Actionが連続スペースなタスクの方が得意なイメージがあります。となるとActionの設計も重要になってきますね。もっと複雑なタスクをやらせて欲しくなった!
AIだけではなく、強化学習の概念とアルゴリズムはゲーム開発中にも活用できると思います。勉強になりました!
明日は25日!クリスマス当日に軍曹が素敵な記事を公開する予定です。みなさんぜひ読んでみてください〜!