こんにちは。東北大学 情報科学研究科 M1の近藤 智文です。Twitterでは@tomokon_0314で活動しています。大学ではネットワーク、SDNの研究をしており、趣味は自宅インフラやリアル脱出ゲーム、ボードゲーム等です。最近は火星から脱出したりしてます 🚀
今回、「Akatsuki Games Internship 2022 Go/GCPコース」に参加し、株式会社アカツキゲームスのATLASチームにて2022/08/01〜2022/08/19の期間で3週間のインターンをさせていただきました!
インターン中に取り組んだタスクやそこで学んだことについて紹介しようと思います。
ATLASの通貨管理基盤について
ATLASにはアカツキゲームス社内のさまざまなタイトルのゲームから利用されている共通の通貨管理基盤があり、クライアント側で動作するライブラリと、課金や通貨の残高管理機能を提供するAPI Serverから成ります。今回私が関わったのは後者のAPI Serverの方でした。イメージとしては以下の図の感じです。
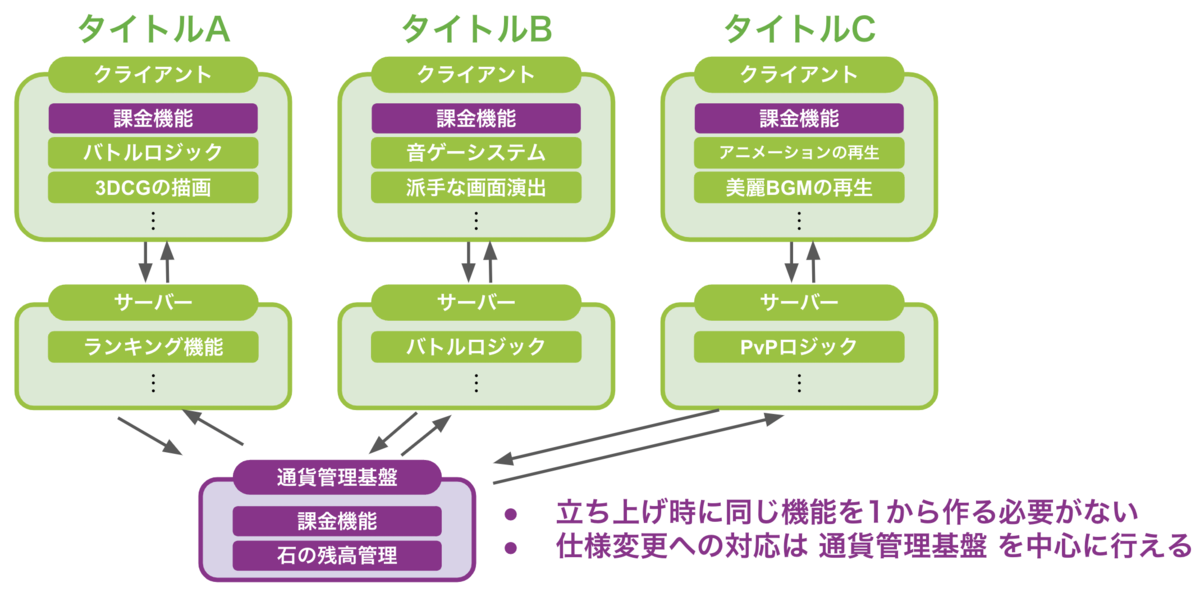
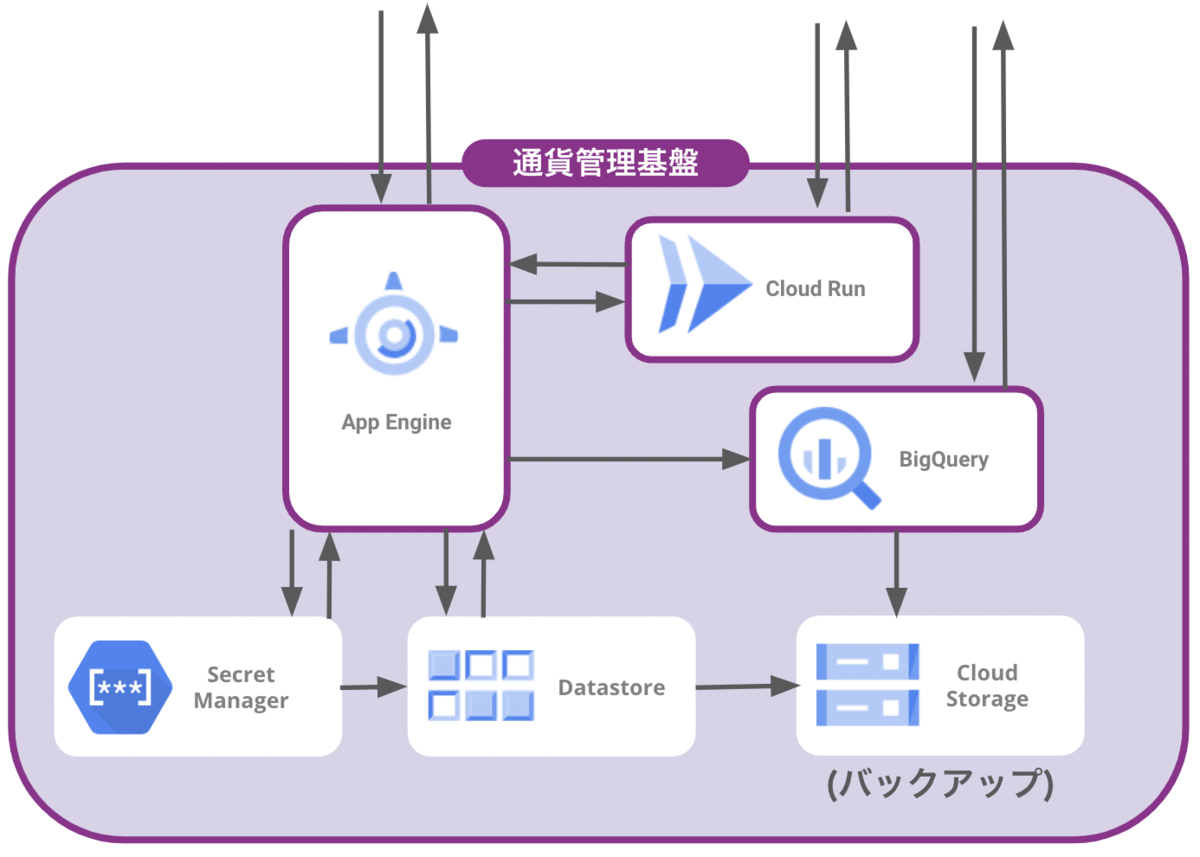
上図の下部の紫の枠で囲まれた「通貨管理基盤」と書かれているAPI ServerはGoで実装されており、GCP のGoogle App Engine (GAE) 上で動かされています。メインのAPIとは別に社内用管理アプリケーションをCloud Run上で動かしたりもしています。インフラの構成は以下のような感じです。
インターンで取り組んだタスク
今回のインターンではATLASの通貨管理基盤のAPI Serverに関する2つのタスクに取り組みました。一つずつ紹介していきます。
APIのレスポンスにおけるステータスコードの修正
通貨管理基盤で扱う通貨には2種類あります。プレイヤーさんが課金によって得た通貨である有償通貨と、それ以外の例えばイベントやログインボーナスで得た通貨である無償通貨です。後者の無償通貨をチャージするためのAPIのエンドポイントにおいて、クライアントからのリクエストとデータベースの情報が不整合を起こして場合にはエラーを示すステータスコードを含むHTTPレスポンスを返すようになっていたのですが、そのステータスコードが本来400であるべきはずであるのに実際には500になっているという問題が生じていました。
HTTPのステータスコードについて簡単におさらいですが、HTTPのステータスコードは3桁の整数で表され、最上位の桁が大まかなレスポンスの種類を示しています。例えば2xxであればリクエストが成功したことを、3xxであればリダイレクトを、4xxであればクライアントエラーを、5xxであればサーバーエラーであることを示します。詳しくは以下のドキュメントを見てみてください。
ではなぜ本来は400で返すべきものを500で返すことが問題になるかと言うと、主に二つの理由があります。
一つ目は、レスポンスのステータスコードによってクライアントの対応が異なる場合があるからです。例えば400エラーであればクライアントは自信が送信したリクエストに何らかの間違いがあることに気づき、間違いを修正して再度リクエストを送り直すことになります。対して500エラーの場合は、クライアントはサーバー側の一時的な不具合かもしれないと思い、時間を置いて何度もリトライ処理をするかもしれません。しかし、実際にはリクエストに間違いがあるため何度リクエストを送信しても成功することはなく、不要なリクエストが何度も発生してしまったり、クライアントが自身の間違いに気づくのが遅くなってしまうという問題につながるかもしれません。
二つ目は、API Server側のエラーレートの誤検知に繋がるからです。例えばAPI Serverで5xxエラーの割合を計測してそれをn%に抑えようという取り組みをしていた場合に、本来は400エラーであるべきものが500エラーとしてカウントされてしまうと、適切なエラーレートの集計ができなくなってしまいます。
そこで、無償通貨チャージのエンドポイントの実装に該当するエラーハンドリングを追加し、クライアントからのリクエストに間違いがある場合は400エラーを返すように修正しました。また各エンドポイントに対するレスポンスのステータスコードはインテグレーションテストによって検証されていたため、テストコードにも修正を加え、無事意図通りに動作していることを確認できました。
アラートの改善
続いてのタスクとして、通貨管理基盤 API Serverにおけるアラートの改善に取り組みました。
タスクに取り組んだ理由は、既存のアラートでは頻繁に (一日に何度も) 通知が飛んでくるのに実際には対応が必要になるような問題が生じておらず、不要なアラートの対応に労力や集中力が奪われてしまっていたからです。また、不要なアラートが頻繁に発生することで「アラート慣れ」してしまい、アラートが起きても「何だ、またアラートの誤作動か」と思ってしまうようになります。そうなると、もし本当に対応が必要なアラートが発生したときにもそのように軽く考えてしまい、対応が遅れて障害の影響が大きくなってしまうという危険性があります。いわゆる「オオカミ少年アラート」というやつです。
このタスクに取り組むために、まずは情報収集に取り組みました。メンターさんやチームメンバからお薦めしてもらった Google - Site Reliability Engineering の資料や家にあって積読していた O'Reilly Japan - 入門 監視 、O'Reilly Japan - SRE サイトリライアビリティエンジニアリング などの書籍を参考に、Service Level Indicator (SLI)、Service Level Objective (SLO)、Error-budget、Burn-rateなど、SREにおけるモニタリングやアラートの考え方やプラクティスについて学びました。調べる前は「SLOとかError-budgetとか聞いたことある!」くらいのレベルだったので、それらの意味や具体的な算出方法、それらをアラートにどう利用するかなどをしっかりと理解することができて非常にためになりました。
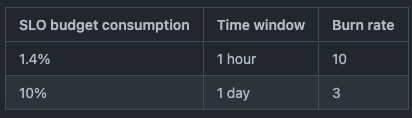
そして、収集した情報を元に通貨管理基盤 API ServerのSLOの見直しを行い、決定したSLOを元にFast-burn、Slow-burn (気になる方は上記リンクを調べてみてください) の2種類の条件からなるアラートを策定しました。下図は実際にGitHubのコメント上で提案したアラートの条件で、上行がFast-burn、下行がSlow-burnとなっています。
あとは策定したアラートをTerraformで記述することで本番環境のGCPプロジェクトに反映し、意図通りに動作することが確認できました。
学んだこと
今回のインターンでは初めて本番環境のGCPに触れ、特にGAEやCloud Monitoringの仕様や使い方について学ぶことができました。特に本番環境のCloud Monitoringのメトリクスやログ等を自由に見させていただくことで、実サービスのリクエストのトラフィックを体感できてワクワクしました。また、Cloud MonitoringのMetrics Explorerでメトリクスを集計してカスタマイズしたグラフを作成する方法や、SLOやアラートの定義の方法など、GCPのドキュメントをじっくり読む時間をいただいたおかげでかなり詳しく知ることができました。また、GCPに限らずSREにおけるモニタリングの考え方・プラクティスについてもさまざまな資料を読み、今まで曖昧な理解だったものをより深く理解することができました。インターン期間の半分、もしかしたらそれ以上の時間を調査に使っていたような気がしますが、じっくりと調査して考える時間をいただけたおかげで最終的に自分もチームメンバも納得のいく形で結果を出すことができたと感じています。
さいごに
3週間という短い期間でしたが、タスクを通してさまざまなことを学ぶことができ、充実したインターンになりました!
メンターの nakahiko さんを始めとしたATLASのチームの皆さんには色々とアドバイスをいただいたりとお世話になりました。本当にありがとうございました 🙇♂️
さいごに出社日に食べたランチの写真を載せておきます 🍽

