はじめまして、7月5日から7月30日までアカツキのサーバーサイドでインターンをさせていただいた光枝と申します。 本記事では私が今回のインターンで取り組んだことについて共有させていただきます。
自己紹介
神戸大学理学部の学部3年生です。 普段は主にWebアプリケーションの開発をやっていて、サーバーは Ruby on Rails、フロントは React/Next (TypeScript) を書くことが多いです。 最近は Go や Kubernetes の勉強などもしています。
インターンの題材
今回のインターンで取り組んだ題材は「負荷試験」です。
私が携わらせていただいたサービスはユーザー数が非常に多いゲームでイベントや新しいガチャが実装された際にはサーバーにかなりの負荷がかかります。
そんな中で当ゲームはメジャーバージョンアップを控えています。 その際に
- 今までの機能が重くなっていないか
- 新機能が重くないか
を検証する必要があり、そのタスクにアサインいただきました。
検証方法
検証にはAWS上に構築した本番環境の数十分の1スケール(以後stress環境と呼びます)を使用しました。 手順は以下の通りです。
1. シナリオの準備
負荷試験には LOCUST という負荷試験ツールを使用しました。
LOCUST は locustfile.py というファイルにシナリオを書くことで、その通りに負荷をかけてくれるツールです。
(他にもアクセスするユーザー数や Hatch rate を設定し、結果を確認するためのGUIを提供しています。)
シナリオは例えば
ログイン → お知らせ確認 → ログインボーナス取得 → ...
のようにユーザーの動きを再現するように、各APIを順番に叩く処理を記述します。
バージョンアップに際して今回着目した新APIを叩く処理をシナリオに追記しました。
(ここではそのエンドポイントを POST /hoge として置きます。)
2. ローカル環境での実行
まず新バージョンがすでに動いている環境のデータベースをコピーしてきて、LOCUST をローカルで実行します。 ここで失敗し続けているAPIがないか確認します。
(例えば特定のAPIが失敗していた場合、そこで処理が止まってしまい想定していた負荷をかけることができなくなったり、その後に続く処理が実行されなくなってしまうのでここで確認する必要があります。)
3. AWS の stress環境に反映して実行
手元で確認が取れたら実際にstress環境で実行します。 stress環境にかかる負荷は
インフラの負荷 → Amazon CloudWatch
アプリケーションの負荷 → New Relic, LOCUST
で確認します。
実行結果
上記の 1 ~ 3 で負荷試験を実施してデータをみたところ、新APIに問題が見つかりました。
| 平均レスポンスタイム (ms) | |
|---|---|
POST /hoge |
2090 |
| 1リクエストあたりのSQL実行回数 | |
|---|---|
| ActiveRecord Model2 find | 396 |
| ActiveRecord Model3 find | 396 |
| ActiveRecord Model4 find | 18.3 |
これは N + 1 問題が起きていると考えられます。 なのでこれを修正して再度負荷試験を行い、どの程度改善されたかを計測します。
実は負荷試験を実施するまでにもいくつか苦労したところ (e.g. 「外部API のモック。これをやらないと外部サービスに対して負荷をかけてしまう」) がありましたが、今回は負荷試験の結果と改善に焦点を当ててお話させていただきます。
発生している問題
まず 「N + 1 問題とは何か」を簡単に説明します。
例えばユーザー(User)というモデルがあり、ユーザーがユーザーHoge (UserHoge)というモデルと関連があるとします。 また1ユーザーにつき、通常複数の UserHoge が関連しているとすると以下の図のような関係になります。
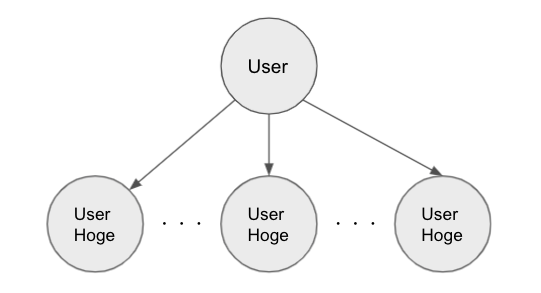
これらのデータが全て必要な場合にUserHoge が N 個あるとすると、このデータを取得するためにデータベースに N + 1 回 (1回は最初に User を取ってくるため) 問い合わせてしまうことを N + 1 問題と呼びます。
これらは本来、工夫することで 2 回の問い合わせですべてのデータを取得することができます。
今回の POST /hoge の問題も N + 1 問題だと予想されます。
調査
まず実際にローカル環境で API を実行して発生したクエリを再現し、該当コード部を読みました。 その結果以下のような構造になっていることが判明しました。
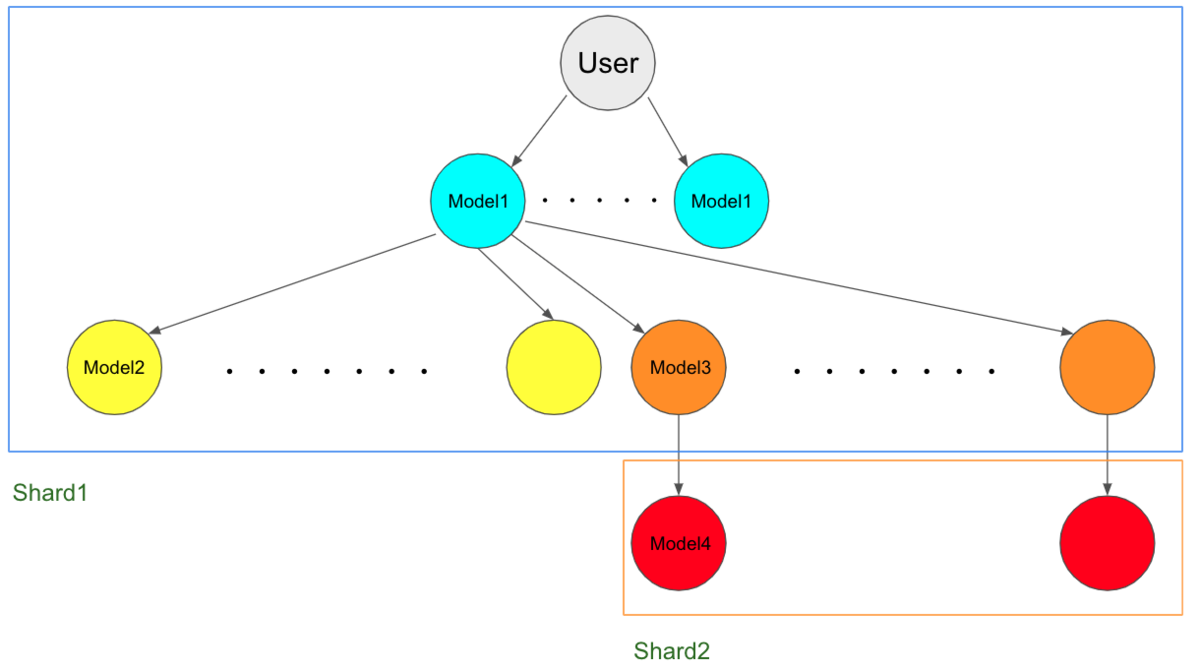
User が複数の Model1 と関連していて、Model1 は複数の Model2 と Model3 と関連があります。Model3 は 1 対 1 で Model4 と関連があります。 またこのサービスはデータベースを水平分散しており、「User, Model1, Model2, Model3」は同一のデータベース(Shard1)にありますが、Model4 だけは別のデータベース(Shard2)に保存されています。
これらのデータをすべて取得してくる必要があったため対策がない場合は
- 1 ユーザーあたり N1 個の Model1 と関連
- Model1 は N2 個の Model2・N3 個の Model3 と関連
- Model3 は N4 個の Model4 と関連
としたとき合計で
N1 × (N2 + N3 + N4) 回
のSQLクエリを発行することになります。(ただし N1 個の Model1 はすでに取得済みとします。)
これが原因で POST /hoge は非常に重くなっていました。
修正に当たっての問題 その1
本サービスのサーバーサイドは Ruby on Rails で書かれています。
通常の N + 1 問題であれば includes メソッドを使うなどで解決できますが、今回の Model4 はシャードが異なるためワンライナーで取ってくることはできません。
Model3 から関連する Model4 を取る際にシャードを変更する必要があります。
この部分は以下のようにして解決しました。
Octoball.using(shard1) do ActiveRecord::Associations::Preloader.new.preload(model1s, [:model2s, :model3s]) end model3s = model1s.flat_map(&:model3s) Octoball.using(shard2) do ActiveRecord::Associations::Preloader.new.preload(model3s, :model4) end
まず Octoball の部分でシャードを切り替えています。
以下のように記述することで #block の部分を指定の shard に接続した状態で実行することができます。
Octoball.using(shard) do # block end
そこでまず Model2, Model3 まで shard1 に接続した状態で preload (ActiveRecord::Associations::Preloader.new.preload(model1s, [:model2s, :model3s])) しておきます。
そして preload した model3s だけ変数に参照渡しして、shard2 に切り替えてから残りの Model4 も ActiveRecord::Associations::Preloader.new.preload(model3s, :model4) で読みます。
このように記述することでシャードを跨いだ関連に対しても N + 1 を回避させることができます。
修正に当たっての問題 その2
全データの取得はこれで問題ありませんでしたが、それでも model4 だけ N + 1 問題が解決しませんでした。
理由としては、その後の model4 を使用する箇所で model3 のアソシエーションを使用していなかったためです。
実装は model4_id を用いて model4 を find_by するコードになっていました。
class Model3 < ApplicationRecord
belongs_to :model4
.
.
.
def model4
unless defined? @model4
@model4 =
if model4_id
Model4.using(shard2).find_by(id: model4_id)
end
end
end
end
なお model4 の関連付けがあるのに model4 メソッドが用意されているのは、毎回シャードを指定しなくてもよくするためです。
(また shard2 は動的に決まっています。shard2 は master/slave 構造を取っており、環境変数のAZを見て最適な slave を返すようになっています。)
上記の記述だとアソーシエーションを利用せずに model4 を取得するため preload したデータを使いません。
そこで以下のように条件を書き加えました。
class Model3 < ApplicationRecord
belongs_to :model4
.
.
.
def model4
unless defined? @model4
@model4 =
if model4_id
if association(:model4).loaded?
association(:model4).target
else
Model4.using(shard2).find_by(id: model4_id)
end
end
end
end
end
association(:model4).loaded? ですでに読み込まれているか確認して、true だった場合はその中身 association(:model4).target を返すようにしました。
改善後の結果
上記の改善を入れて、再度負荷試験を実施したところ以下のようになりました。
| 改善前の平均レスポンスタイム (ms) | 改善後の平均レスポンスタイム (ms) | |
|---|---|---|
POST /hoge |
2090 | 296 |
| 改善前の1リクエストあたりのSQL実行回数 | 改善後の1リクエストあたりのSQL実行回数 | |
|---|---|---|
| ActiveRecord Model2 find | 396 | 1 |
| ActiveRecord Model3 find | 396 | 1 |
| ActiveRecord Model4 find | 18.3 | 1 |
完全に N + 1 が消えて、各 Model がそれぞれ1クエリで取れるようになったのがわかります。
また POST /hoge 自体もかなり高速化されました。
インターンでの学び & 感想
インターンに参加する前は負荷試験について言葉だけ知っている状態でした。
しかし実際に
負荷試験の準備(シナリオ作成、APIの失敗がないかのチェック及び修正、ローカル実行で確認)
↓
stress環境で負荷試験実施
↓
CloudWatch, New Relic, LOCUST でメトリクスなどを確認
↓
問題があった場合は改善
↓
再度負荷試験を実施して改善効果を検証
という一連の流れを体感することができました。
またシャードを跨いだ関連付けの取得やActiveRecord 内部の仕様についても理解を深めることができました。
実は事前面談で「インフラ系のタスクをやってみたい」とお話していてこのタスクを用意していただきました。
なので私がやりたいと言ったことをやらせていただき、また手厚いサポートのもとたくさんのことを学ばせていただきました。
約3週間本当にお世話になりました。ありがとうございました!!!